前言
久闻scrapy大名,一直想找机会了解一下这框架,在兴趣的驱动下学习了一下简单的scrapy的使用。虽然上次用java做的一个爬虫,但是后来觉得也算不上什么爬虫吧,只能算模拟http请求和http响应的处理、json的序列化和反序列化、excel文件的读取和写入而已,很多爬虫需要处理的东西也并没有处理。
但是scrapy就不一样了,作为一个成熟的爬虫框架,scrapy有以下几点优势。
- 内嵌了CSS选择器和XPath解析器用于提取HTML/XML的信息。
- 提供了一个shell控制台用于测试css和xpath的表达式。
- 良好的架构设计:middleware、pipeline。
- 成熟的请求调度器。
备注: 以上特性来自于scrapy官方文档
scrapy还有很多其他的特性,我在实践中比较常用的就是上面这几项。
另外,上次爬取动态页面的时候,采取的策略是分析AJAX请求的URL然后自己构造请求。这种方法比较麻烦,需要自己去分析请求,这次我们采用selenium+headless-chrome,以浏览器自动化的方式爬取数据。
技术框架
编程语言:python
库:scrapy、pymysql、selenium
工具:headless chrome
| 框架 | 说明 |
|---|---|
| scrapy | python著名爬虫框架 |
| pymysql | python数据库访问框架 |
| selenium | 浏览器自动化框架 |
| headless chrome | 命令行运行的chrome |
数据流
在研究数据流之前,我们首先看一下scrapy设计的架构。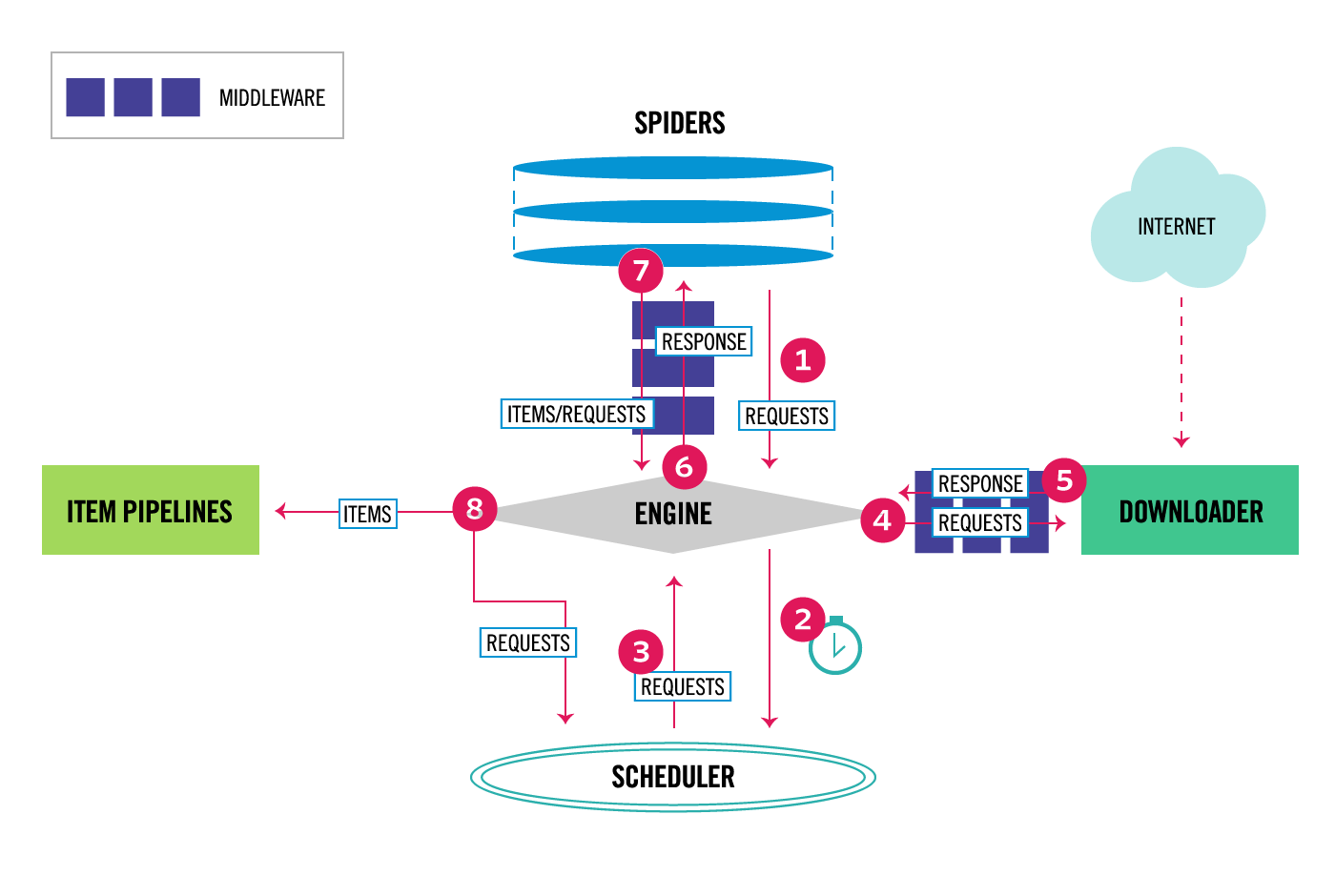
- spider创建Request对象。
- request对象经过SpiderMiddleware
- Engine获取了spider的请求。
- Engine将请求发送给scheduler调度,继续拿下一个请求。
- scheduler调度请求,发送到downloadMiddleware。
- 根据downloadMiddleware
process_request()方法的返回结果,选择继续发送给downloader或者是返回response给Engine - Engine将response发送给spider middleware
- spider middleware将response发送给spider
- spider 调用注册的回调函数(默认
parse()) - 根据返回结果调用pipeline和继续将请求发送给Engine
制作了一个序列图如下: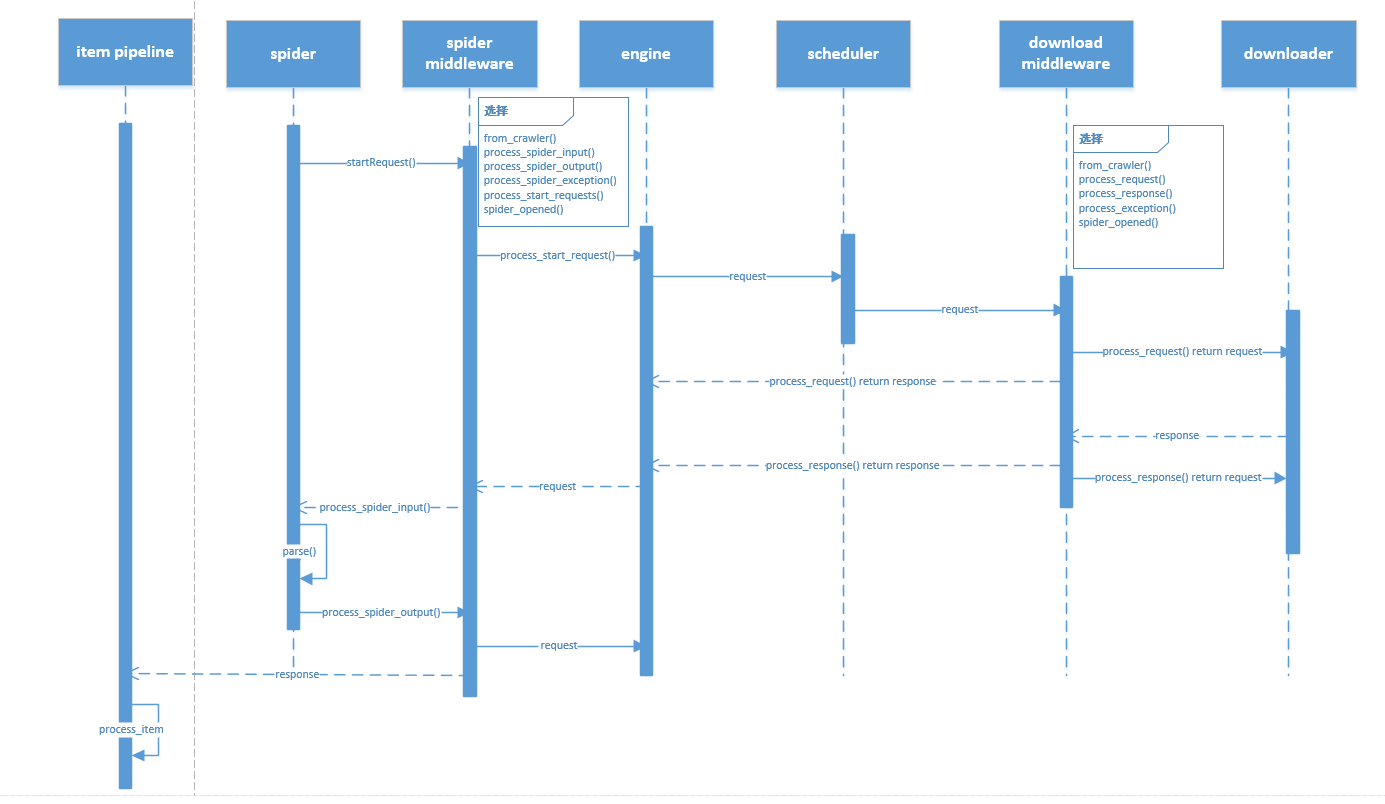
项目实战
下载chrome driver,将可执行文件添加到环境变量。windows下直接下载chrome,Linux命令行下载chrome步骤如下:
1 | deb版本地址:https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb |
然后安装python需要的几个库
1 | pip install pymysql |
下面我们爬取某二手车网站的数据,爬取思路大致如下:
- 获取某二手车网站的url。
- 向该URL请求数据。
- 写一个download middleware,拦截该请求,将请求交给chrome处理。
- 得到渲染好的HTML文档后,编写css、xpath表达式提取数据。
- 编写一个item pipeline,将数据写入数据库。
项目源代码在这里,在此不过多叙述实现的细节。
反爬虫与反反爬虫
在完成这个项目的过程中,在知乎上看到一个关于反爬虫的回答[1]总结得挺有意思的。内容涵盖了反爬虫的方方面面,我总结一下他提到内容:
- 只允许指定UserAgent的请求。但是这个请求头太好伪造啦,所以这样方法应该根本不可行。
- IP白名单。就是只让一部分IP访问,但是这对web应用是不现实的啦。因为web是公开的。
- 带有浏览器特征的AJAX请求并且前端进行特殊处理后渲染。这个时候呢就是用selenium+headless-chrome啦,浏览器驱动+浏览器自动化技术。
- 监控请求频率和时段,同时设置验证码。请求频率和时段的话,控制爬取的时间段和频率就可以了。传统验证码的话,可以用机器学习的方法图像识别。
- 传统验证码容易被图像识别,所以现在产生各种拖动滑条、点击图中的指定的字这种验证码,这种验证码用机器处理难度还是比较大的。但是呢,可以花钱请专门的“打码”团队帮忙,这个在爬虫领域还是很常见的。
在实践过程中,爬取某二手车网站的时候,直接模拟http请求是不可行的,因为会提示如下信息: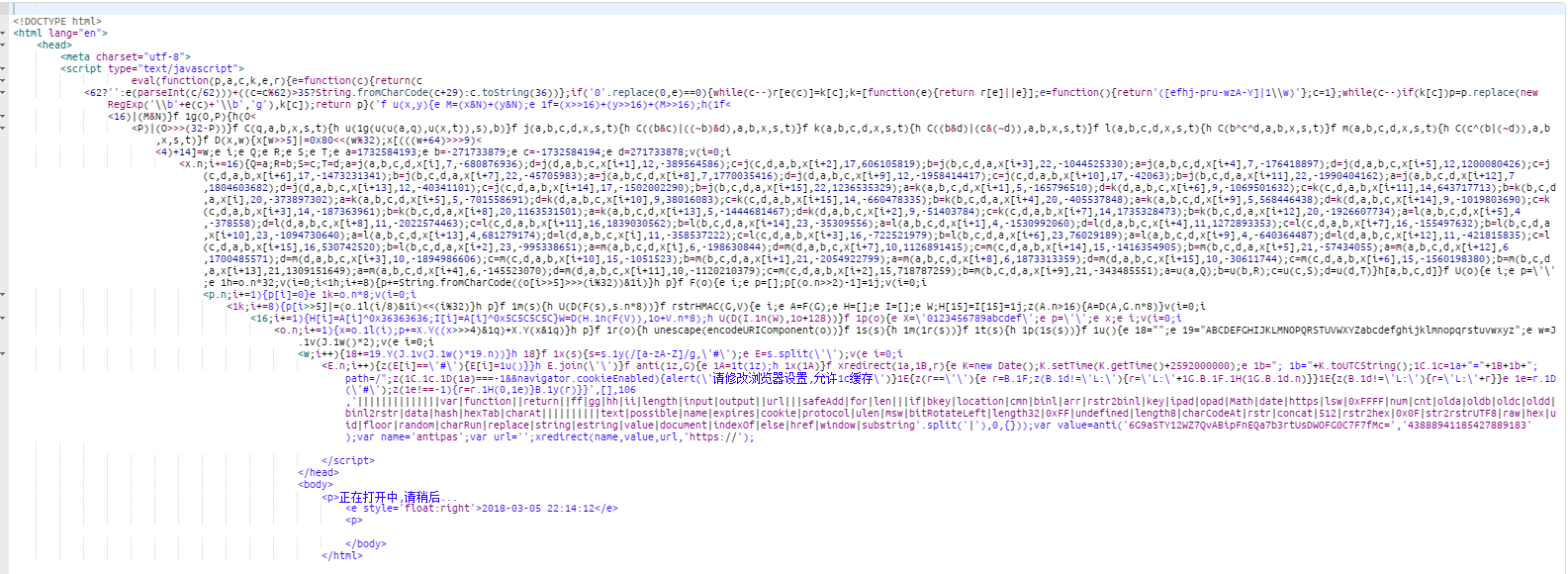
这就是典型的利用浏览器特征反爬虫的,就是不允许非浏览器的请求。解决办法就是自动化浏览器请求。
另外我自己也简单尝试了一下图像识别验证码的。当时使用的是tessract和PIL,因为我没做二值化处理和训练模型,所以是失败了。因为不想再这方面投入更大的时间,所以就此作罢。
最后,我在程序也实现了指定时间段和频率控制的功能。指定时间段的话也很简单,就是获取当前时间,是指定时间就运行非指定时间睡眠就可以了。控制的频率的话,加入延迟的就好。
浏览器自动化技术
在这次爬虫的过程中,接触到了浏览器自动化技术。其实呢,这项技术本身是用来进行浏览器自动化测试的,只是很多人也用它进行爬虫。浏览器自动化是一个有趣的事情,让我们简单看看它的效果。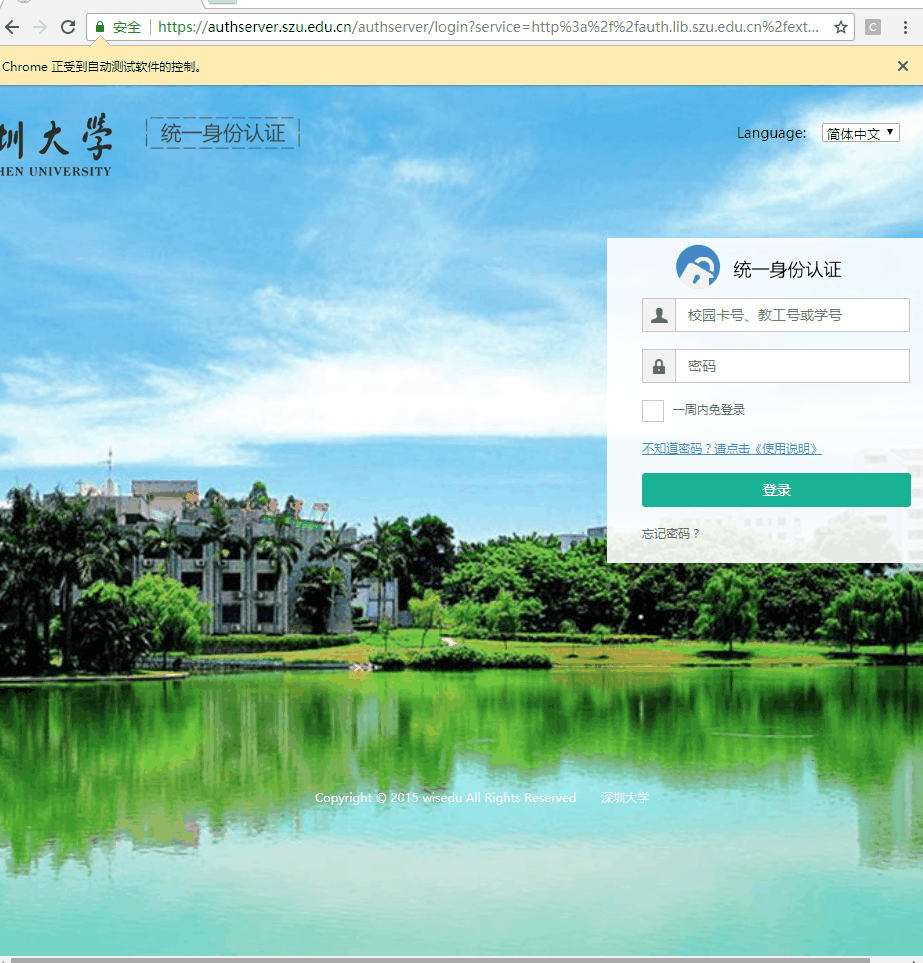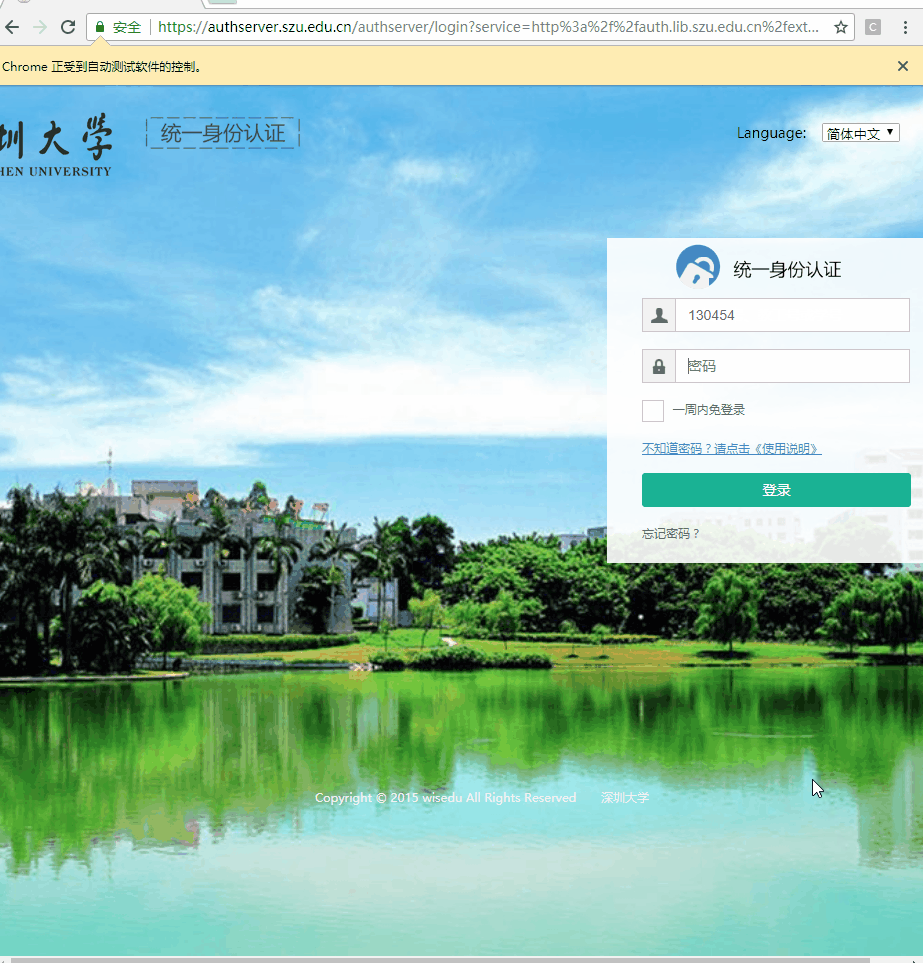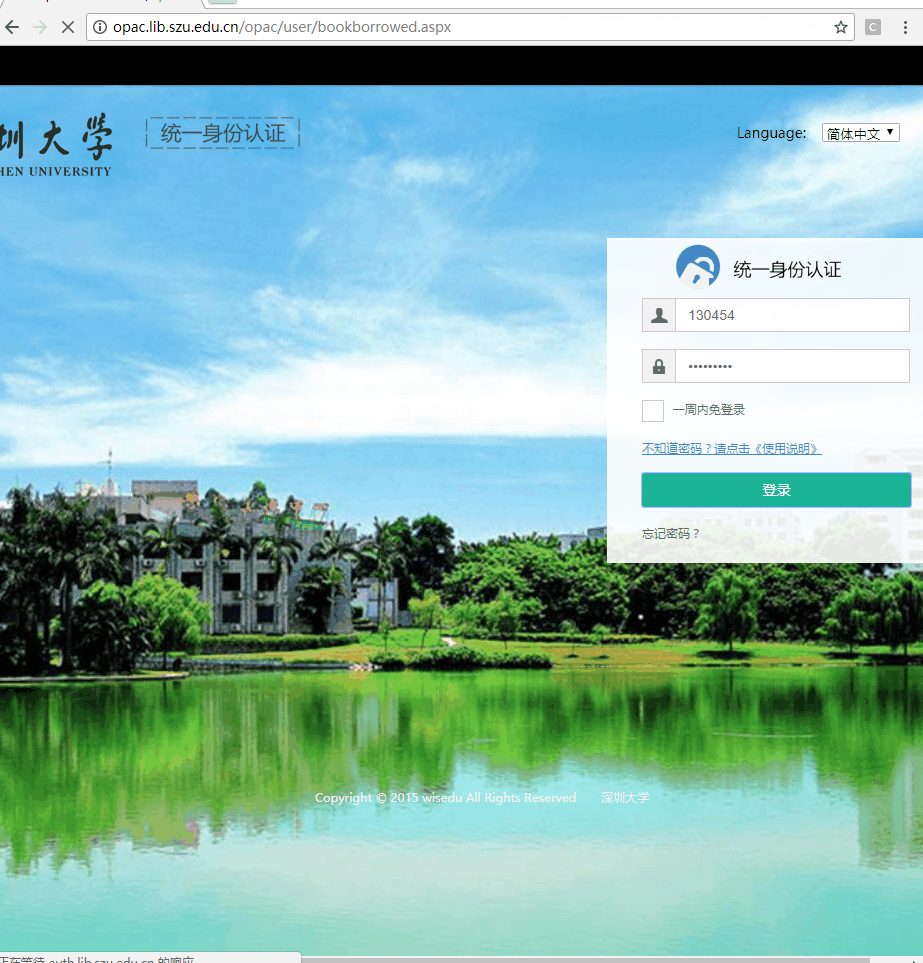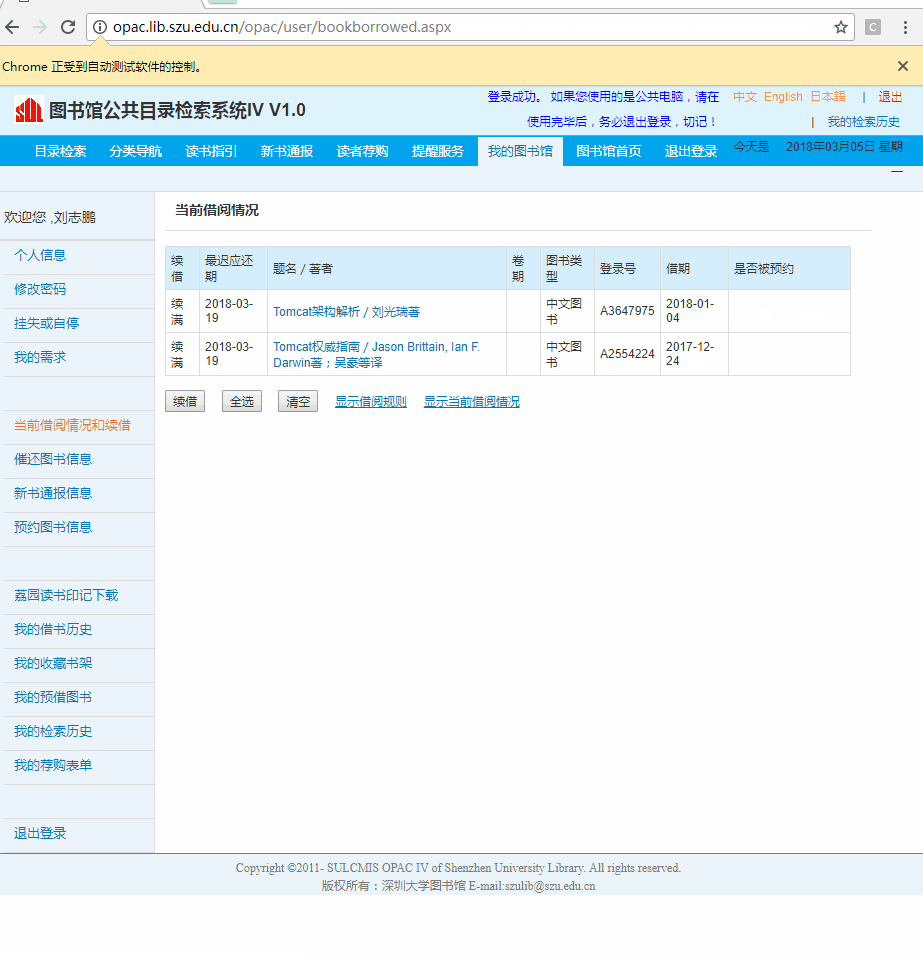
这是一个自动化登录的例子,哈哈哈,是不是有点酷第一次看到可以自动化还是有点小激动的
另外,很多人都用过headless browser,不过网上很多文章都是使用PhantomJS的,而我为什么不用呢,主要是因为PhantomJS作者在2017年4月13日就宣布停止维护和更新它啦~因为在无界面浏览器领域,chrome出一个版本,所以PhantomJS的作者就停止维护了,以下是他的帖子。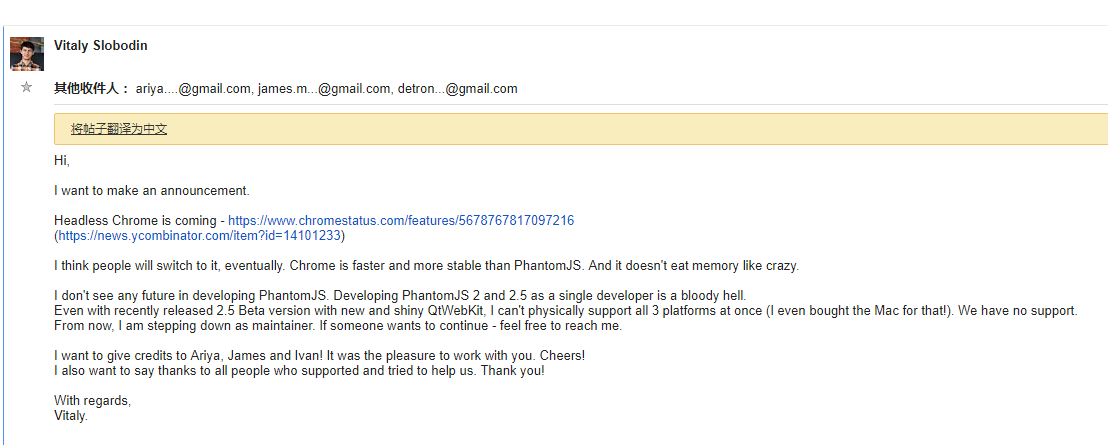
原文链接
作者主要是观点是认为headless chrome比PhantomJS更加流畅和稳定,而且更节省内存。而且作者是自己一个人开发的,(大神收下我的膝盖)所以就停止维护这个项目啦。
最后,其实浏览器自动化的话,除了使用selenium外,在这次爬虫过程中还发现了另外两个库puppeteer和nightmare。第一个是google-chrome官方团队做的,而且更新频率还挺高的挺多人维护的。这两个框架就没时间研究啦,只是了解到,记录一下。
附录:
“结语”
实践是检验真理的唯一标准。知道是怎么样和能够做出来是两回事。作为一个工程师,还是要多多实践的。做这个项目前后用了两周的时间,经历了学习python的简单使用、阅读scrapy的官方文档、阅读selenium文档、学习css选择器和xpath表达式、实现项目、部署上线。
另外在项目过程中也阅读了大量的英文文献,本来也想着先看看中文的书籍先的,但是感觉书籍里面太多无关紧要的内容了,所以还是选择了阅读英文文献。在此过程中阅读英文文献有以下几个优点:
- 系统、全面。
- 带有大量demo、samples。
- 一手信息,更新及时。
当然缺点也有:
- 阅读效率低(主要还是自己英文渣渣)
学好英文多重要啊!还是继续好好学习吧!