背景
最近女朋友需要利用tableau来做数据可视化的作业,要做数据可视化,那首先可定得要有数据。她们打算用八爪鱼等爬虫软件来抓取数据,结果没成功,原因不明。然后跟我吐槽了一下这个事情,刚好我最近也要学爬虫,本着项目驱动学习的理念,就直接选择了这个项目来练手了。
准备工作
编程环境:
1 | IntelliJ IDEA 2017.1.5 |
编程环境如上所示,因为我Java语言比较熟悉,所以编程语言选择了Java。虽然Java做爬虫语法上面比较累赘,但是Python还没学会,就凑合着用Java写了。
流程
我认为的爬虫的流程主要有以下几步
- 确定目标:确定要抓取的网站和需要抓取的内容。
- 分析数据请求:利用浏览器的控制台分析网站数据请求的方式(同步请求还是异步请求)。
- 模拟请求:构造请求,获取数据。
- 分析数据:分析数据,提取有效信息。
- 存储数据。将数据存储到本地。
实践过程
确定目标
我要抓取的网站是淘数据的店铺监控下面的鸿星尔克、德芙、Opus三家店铺的数据,具体的数据如下图所示: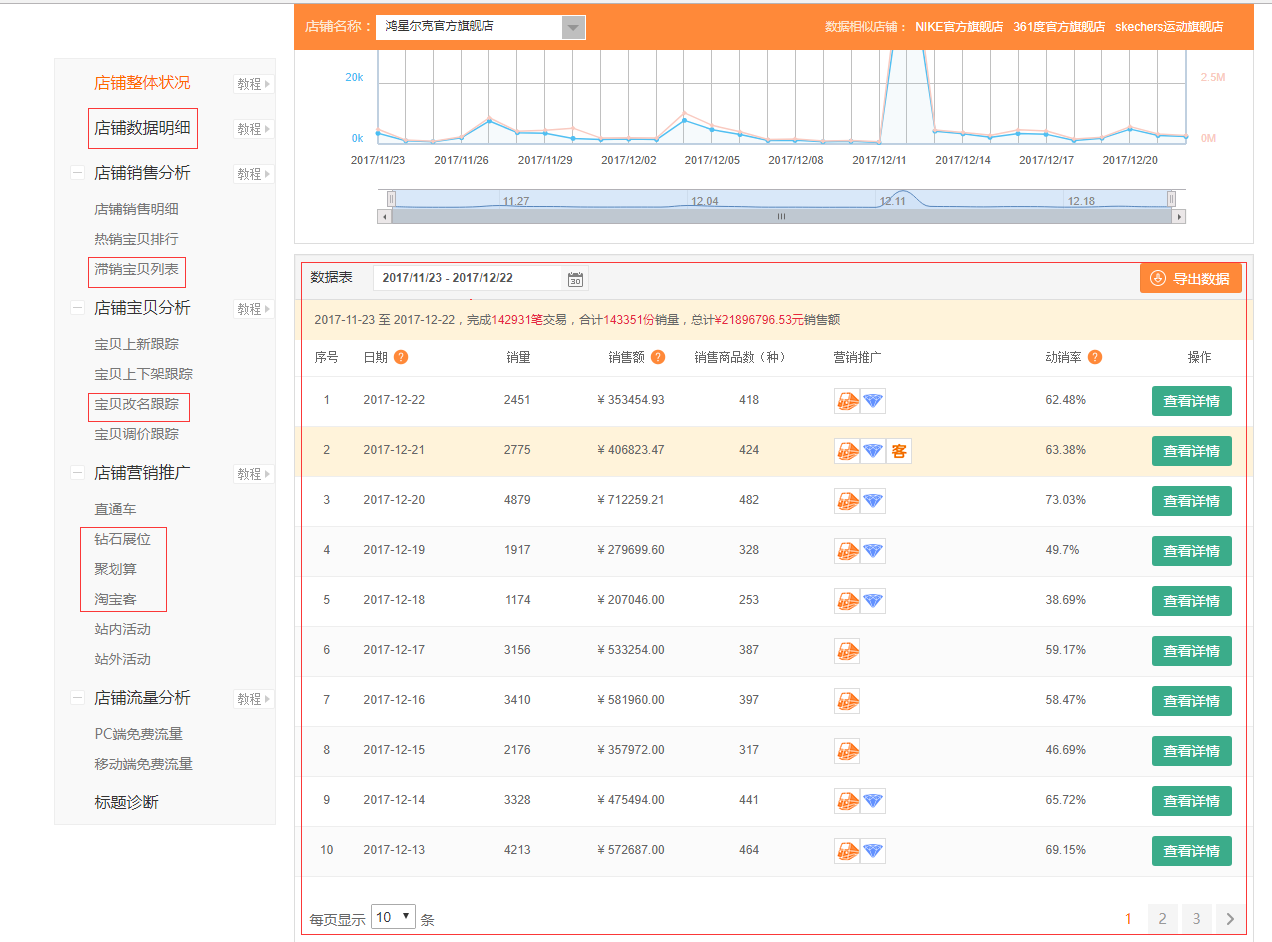
主要包含店铺的数据明细、滞销宝贝、宝贝的上新跟踪、宝贝的改名记录、钻石展位、聚划算、淘宝客。
分析数据请求
打开chrome浏览器,F12打开控制台,点击elements审查元素,通过元素审查我们可知我们需要爬取的数据是通过Ajax异步请求的。接着点击network标签查看网络请求,点击XHR子标签查看Ajax请求,分析请求列表,找到我们需要的请求,单击查看请求详情。
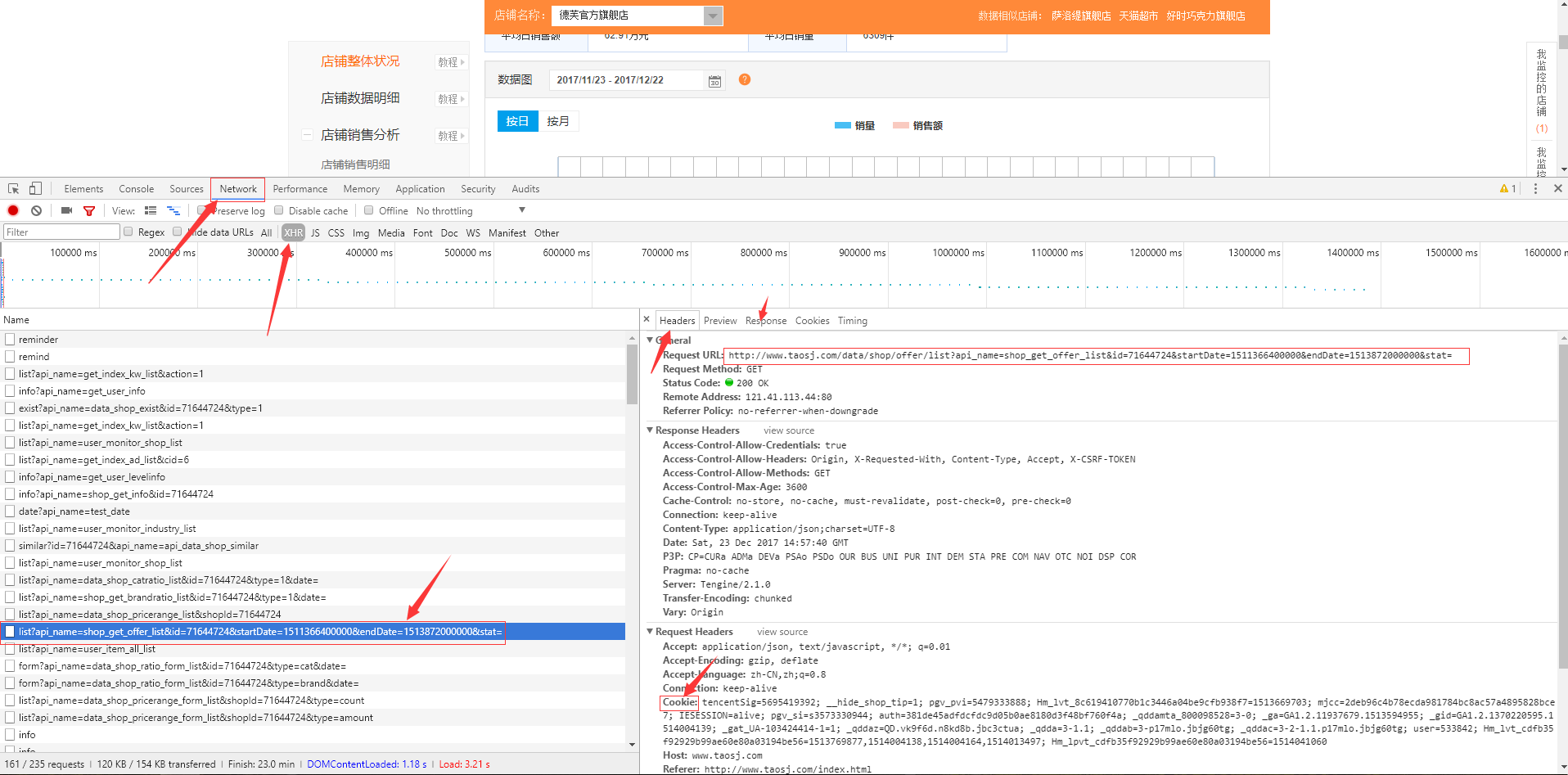
PS: 浏览器都是通过HTTP协议进行数据交互的,所以要爬虫的话,还是需要对HTTP有一定的了解。可以参考《HTTP权威指南》、《图解HTTP》等书籍。
从图中我们可以很明显地得到包括请求和响应在内的Http的详细信息,包括请求的方法、请求的URL、请求的主机、请求的头部以及响应状态码,响应体的内容。Http的每个头部都有其含义,具体请参阅《HTTP权威指南》。在这里我们只关心和我们本次请求相关的内容,整理如下:
| 字段 | 内容 |
|---|---|
| 请求方法 | GET |
| 请求URL | http://taosj.com/...../....stat |
| Cookie | 主要关心auth字段 |
请求URL还可以进一步分析其参数组成。以图中的URL为例,http://www.taosj.com/协议和主机地址,data/shop/offer/list主机下的目录,api_name=shop_get_offer_list...stat=长长的参数列表。
因为访问的数据是需要认证的,常见的认证方式有cookie和token(OAuth2.0)。经分析报头和尝试请求发现,网站是采用cookie认证的,而且主要的认证cookie字段是auth。
接着分析响应体,响应体是JSON格式的字符串(关于JSON可以关注其官网)。
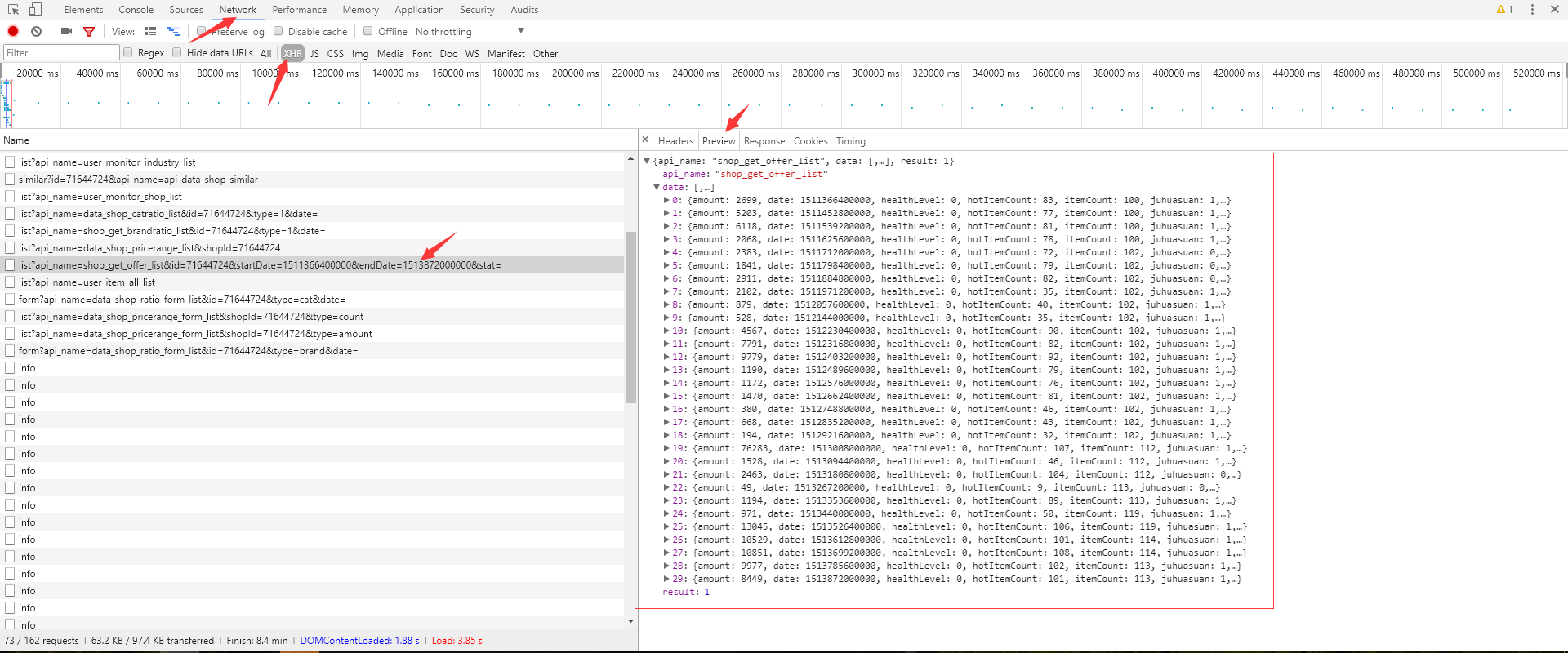
模拟请求、分析数据、存储数据
经过上面的分析,我们已经知道了网站数据请求的方式、数据认证的方式、还有请求相关的信息。接下来就可以开展编码工作了。
编码的环境前面已经介绍了,接下来介绍一下使用的开源库。
okhttp: 负责http网络请求。*json-java: java端json实现。gson: google官方的json解析库。poi: apache开源的excel操作库。
项目构建工具使用gradle,构建脚本如下,源码在最后。
1 | group 'uzpeng' |
首先,根据浏览器控制台的响应信息,使用GsonFormat插件生成实体类的信息。然后,对照网页显示,确认每一个字段的意义。接着,根据前一个步骤获取的Url和参数信息定义好Url和参数。接着,构造http请求,拿到数据。最后,分析数据,写入excel文件。
我们请求的三个店铺都是不需要认证的,如果需要访问其他店铺数据的话,就需要登录。然后照着上面的分析请求的方法,取出cookie的auth字段,最后在构造请求的时候添加cookie头部信息。
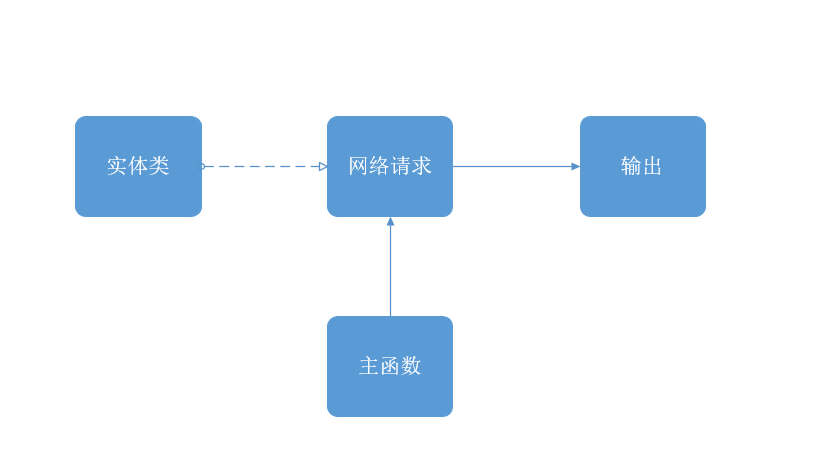
接着介绍一下代码实现,其主要包含以下四个模块:主函数、实体类、网络请求、写入文件。
网络请求的主要函数如下:
1 | public Response request(String url){ |
请求很简单,传入我们分析得出的Url和cookie信息,构造请求,然后同步执行,返回结果。
项目整体的数据流大致如下:
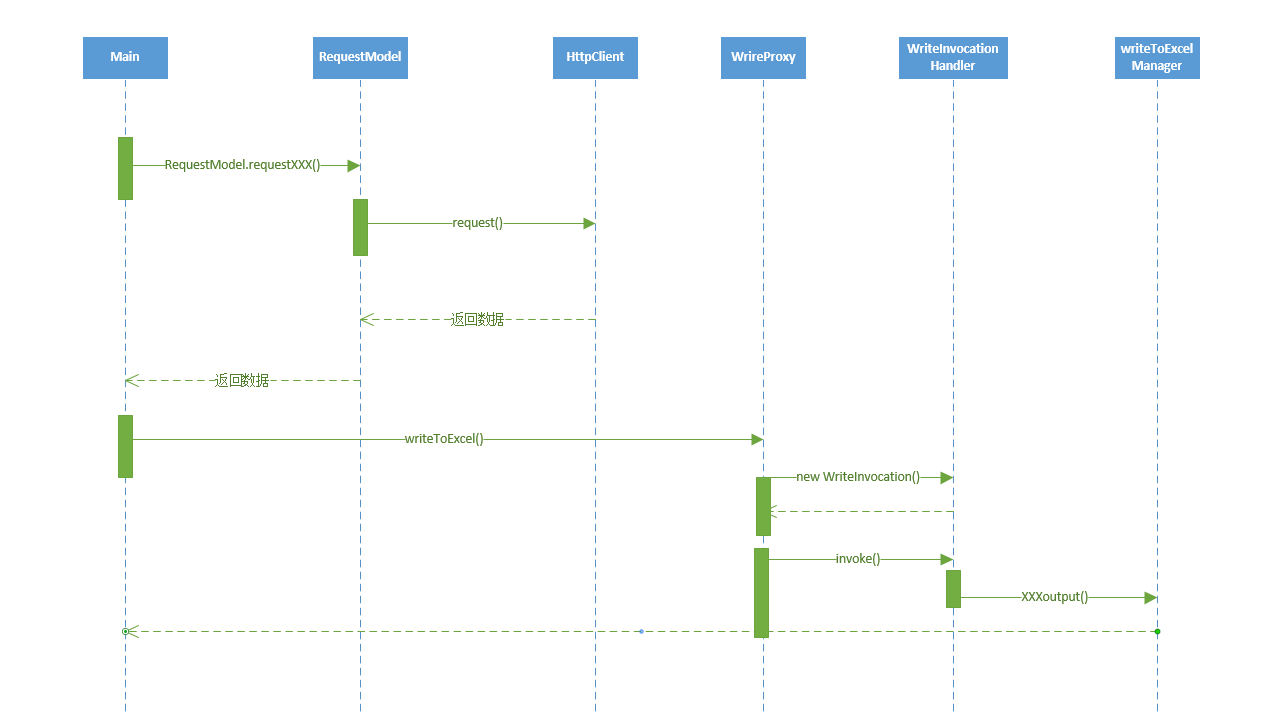
main函数创建RequestModel,调用RequestModel的requestXXX方法。RequestModel调用HttpClient的request方法。- 根据返回的数据调用
WriteToExcel()方法。 writeProxy创建动态代理。- 动态代理的方法里面调用
writeIntoExcelManger的outputXXX()方法,最后写入excel。
代码实现有两点值得提一下:
一是利用jdk动态动态代理,实现AOP,将写入excel的具体内容的代码插入创建excel工作簿和写入本地磁盘之间。
1 | WriteInvocationHandler outputInvocationHandler = new WriteInvocationHandler(); |
二是利用buidler模式构造Url参数
1 | static class ParamBuilder{ |
这里我们将分析数据和存储数据合并在了模拟请求里面,这是因为我们要做的这个爬虫比较简单,数据都是JSON的格式返回回的。如果数据格式比较复杂(如嵌在网页里),则需要构造正则表达式或者利用一些工具分析。同时,因为我们爬取的数据量不太而且不需要持久存储,所以我们直接输出在excel里面了。但是,实际应用中(如全站爬虫),爬取的数据量一般很大,而且需要持久存储、去重、更新维护等等。因此,我们一般会使用数据库,这会让存储数据变得复杂一些。
遇到的问题和解决方案
问题:Gson解析错误,提示类型不匹配
原因:这个问题是由于GsonFormat产生的错误,由于price相关字段的数值为浮点型,但是我们取样的json里面的类型是int,所以会导致解析异常。
解决方法:只要将price相关的字段都改为double型即可。
问题:Gson解析错误提示Unterminated object at line x column xxx
原因:根据堆栈日志可以定位到json发现,json里面存在类似title":"\\"Nike 耐克官方 NSW \\"\\"LET THERE BE AIR\\"\\" 大童(男孩)T恤 863808\\"这种字符串,这明显是不符合JSON要求的。
解决方案:写一个正则表达式,把非法字符串替换成空串即可。
PS:吐槽一下,其实这是他们后台的一个bug,他们的页面也无法访问这种类型的数据,会提示错误。。。
分析
至此,我们就实现了一个最简单的爬虫了。现在我们能够将一些接口的数据爬取回来并且写入本地excel文件了。在实现的过程中还利用了builder模式和JDK动态代理增加代码可读性和减少重复性代码。但是,爬虫的内容绝对不止这么简单,我们这个这么简单一方面是因为我们进行爬虫的网站没有做防爬虫机制。另外一方面,我们的爬取的数据是异步请求的,所以从获取到解析都是相对容易的。但是大量的网站的数据是同步获取的,数据都是嵌入在html代码里面,这个时候就需要我们分析html代码。
常见的防爬虫措施有以下几种:
- 在网站的robot.txt文件里面声明哪些是爬虫可以访问的数据。
- 同一IP大量请求后,屏蔽该IP一段时间。
- 对于请求频率过高的请求要求验证码或谷歌人机验证。
豆瓣是防爬虫做得比较严格一个鲜明的例子。我曾经试过在正常浏览的情况下,就是因为浏览得快一点,就在短时间内被多次要求输入验证码。
既然防爬虫有那么多措施,那么爬虫要怎么应对呢?其实也是有解决方案的。对于封IP的行为,采用公开的IP池的方式,每次使用不同的IP即可。对于请求频率过高要求验证的问题,第一,可以控制请求的频率,第二,人工输入验证码。显而易见,由于web是公开的特征,所以爬虫还是很难完全封掉的。因为你无法准确地判断服务器接收到的请求是爬虫发出的还是用户发出的,所以只能封禁一些明显是爬虫访问的请求,但是爬虫也可以不断地改进从而最大程度模拟用户请求的。
结语
如上所述,这只是一个简单的爬虫例子,但是麻雀虽小,五张俱全,还是能完整体现整个爬虫的流程的。另外,java爬虫确实是有点累赘,而且大量Java Bean的创建也需要花费不少的时间。最近在学习python,学好之后可以使用python的爬虫框架scrapy去爬取一些带有防爬虫的和多重认证的网站,而且还可以把数据存储在数据库里面、做一些去重等等的工作。爬虫是一个很有趣的过程,有很多东西可以研究的。
本次的爬虫就到这里啦,下次做了更复杂的爬虫可以再来分享一下。